一款基於Java Swing开发的開源采集軟件
丑牛迷你採集器是一款基於Java Swing開發的專業的網絡數據採集/信息挖掘處理軟件,通過靈活的配置,可以很輕鬆迅速地從 網頁上抓取結構化的文本、圖片、文件等資源信息,可編輯篩選處理後選擇發佈到網站
主要功能如下
爬蟲配置參數(CrawlScope): 存儲當前爬蟲的配置信息,如採集頁面編碼,採集過濾器列表,採集種子列表,爬蟲持久對象實現類等,CrawlController根據配置參數來初始化其他模塊。 字符集幫助類(CharsetHandler):根據當前爬蟲配置參數中字符集配置來初始化,備整個採集過程使用。 HttpCilent對象(HttpClient):根據當前爬蟲配置參數初始化HttpClient對象,如:設置代理,設置連接/請求超時,最大連接數等。 HTML解析器包裝類(HtmlParserWrapper):對HtmlParser解析器進行特殊化封裝,以便滿足採集任務的需要。 爬蟲邊界控制器(Frontier):主要是加載爬行種子鏈接並根據加載的種子鏈接初始化任務隊列,以備線程控制器(ProcessorManager)開啓的任務執行線程(ProcessorThread)使用。 爬蟲線程控制器(ProcessorManager):主要是控制任務執行線程數量,開啓指定數目的任務執行線程執行任務。 過濾器工廠(FilterFactory):註冊當前爬蟲配置參數中過濾器集合,供採集任務查詢使用。 主機緩存(HostCache):緩存HttpHost對象。 處理器鏈(ProcessorChainList):默認構建了5中處理鏈,依次是,預取鏈,提取鏈,抽取鏈,寫鏈,提交鏈,在任務處理線程中將使用。 預取鏈:主要是做一些準備工作,例如,對處理進行延遲和重新處理,否決隨後的操作。 提取鏈:主要是下載網頁,進行 DNS 轉換,填寫請求和響應表單。 抽取鏈 : 當提取完成時 , 抽取感興趣的 HTML 和 JavaScript 等 。 寫鏈:存儲抓取結果,可以在這一步直接做全文索引。 提交鏈:做和此 URL 相關操作的最後處理。
輸入123456密碼離綫運行
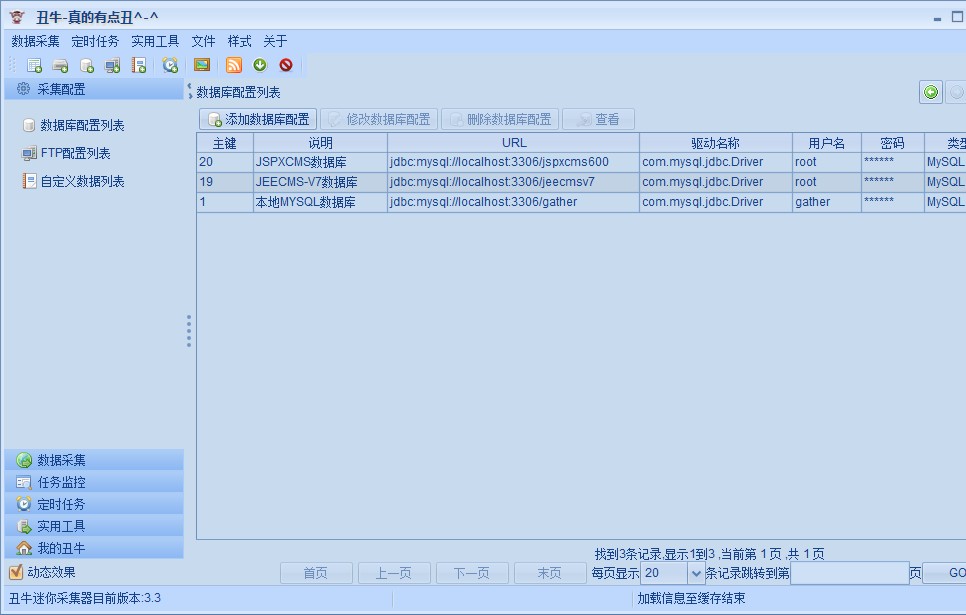
首先要配置MySQL數據庫的賬號信息
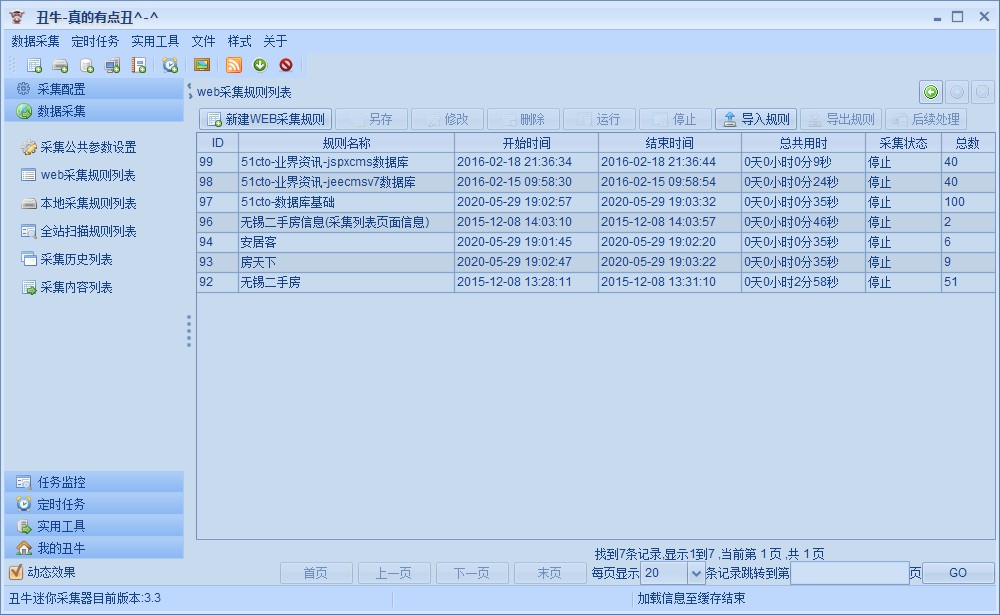
修改採集規則,已經存在採集規則演示,方便新手入門
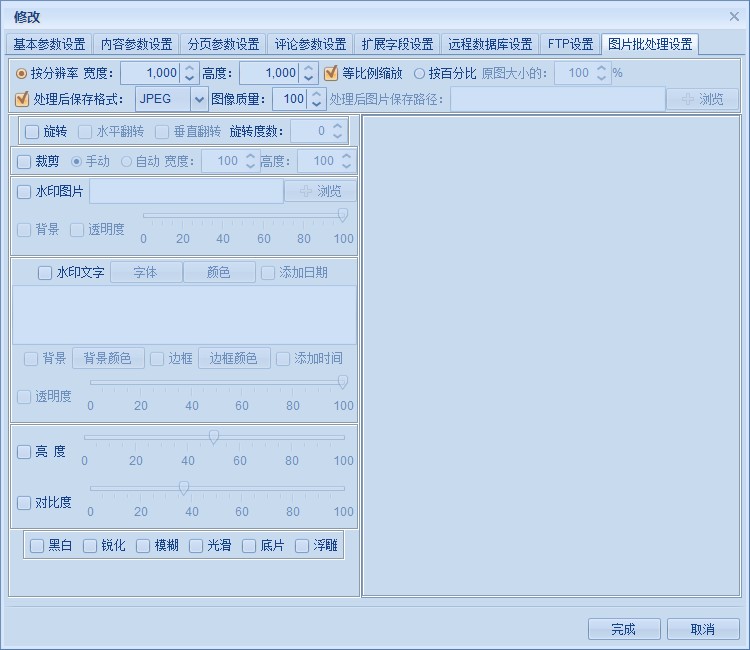
圖片處理功能也非常的強大,
總的來説這是款非常不從的WEB採集軟件,有興趣的可以看看